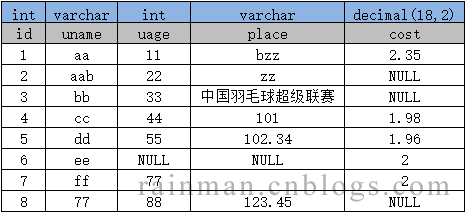
1.下载工具包 scrapy_redis(如果使用的是虚拟环境,先进入虚拟环境再下载)2.配置项目的settings文件,配置scrapy项目使用的调度器以及过滤器如果你想在redis中存储一份,可进行以下操作:(也可以跳过此步)3.修改...

1.下载工具包 scrapy_redis(如果使用的是虚拟环境,先进入虚拟环境再下载)

2.配置项目的settings文件,配置scrapy项目使用的调度器以及过滤器

如果你想在redis中存储一份,可进行以下操作:(也可以跳过此步)

3.修改spider爬虫文件,继承RedisSpider类。

4.如果连接的有远程服务,比如mysql,redis等,需要将远程服务连接开启,保证在其他主机上能够成功连接


5.配置远程的Mysql及redis地址

为确保每一台主机正常连接,要关掉防火墙

6.远程连接redis

7.如果redis想访问远程的redis服务器,需要解除保护模式
做法
1) 在远程服务器登录redis-cli
2) 输入命令
config set protected-mode "no" 回车
8.连接redis客户端,添加爬虫文件

9.如果连接不成功,可尝试以下操作:

织梦狗教程
本文标题为:基于scrapy_redis部署scrapy分布式爬虫


基础教程推荐








猜你喜欢
- Python常见库matplotlib学习笔记之画图中各个模块的含义及修改方法 2023-07-27
- redis乐观锁与悲观锁的实战 2023-07-13
- Mariadb数据库主从复制同步配置过程实例 2023-07-25
- oracle数据库排序后如何获取第一条数据 2023-07-24
- oracle19c卸载教程的超详细教程 2023-07-23
- redis 数据库 2023-09-13
- Java程序员从笨鸟到菜鸟(五十三) 分布式之 Redis 2023-09-11
- Python安装第三方库的方法(pip/conda、easy_install、setup.py) 2023-07-28
- SQL Server如何设置用户只能访问特定数据库和访问特定表或视图 2023-07-29
- Windows10系统中Oracle完全卸载正确步骤 2023-07-24